
阿里云通义千问团队开源两款语音基座模型 语音辨认作用优于OpenAI Whisper模型
阿里云通义千问团队日前在 Github 上开源了两款语音基座模型 SenseVoice 和 CosyVoice,前者用来辨认语音、后者用来生成语音,这两款模型在功能方面也十分杰出,其间 SenseVoice 辨认作用优于 OpenAI Whisper 模型。
这两款模型都是彻底开源的,选用 Apache 2.0 许可证,因而无论是个人、开发者仍是企业都能够免费下载模型布置后运用,能够成为 Whisper 等付费 API 模型的代替。
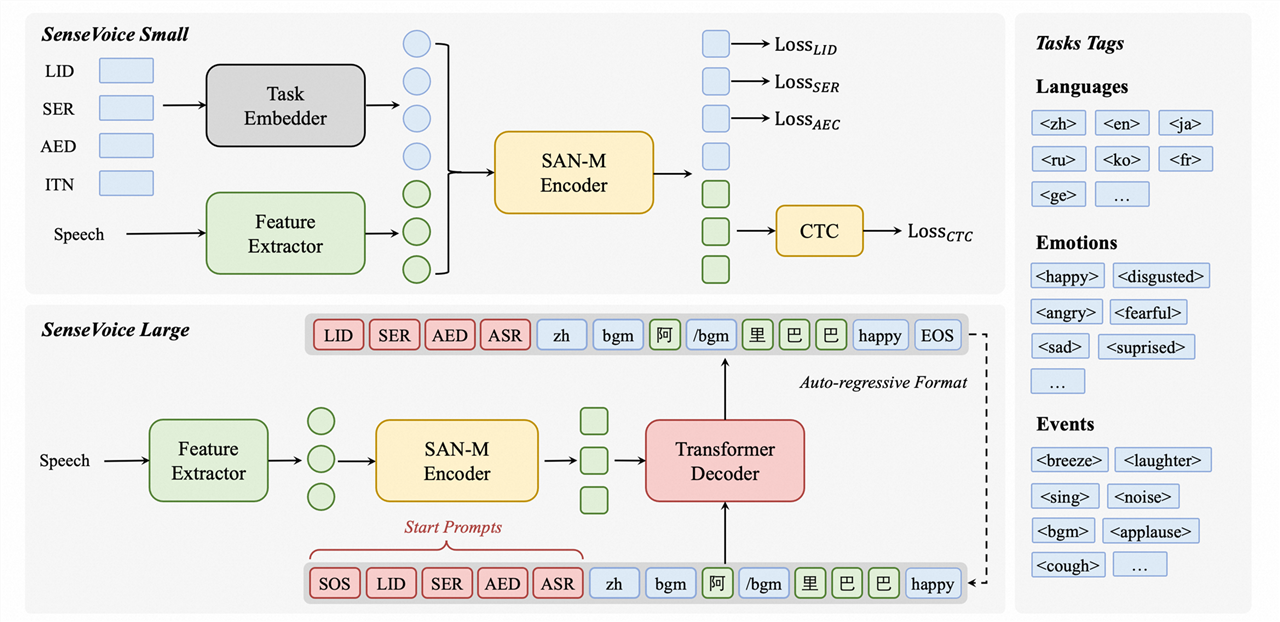
SenseVoice 模型:
SenseVoice 多言语音频了解模型,支撑语音辨认、语种辨认、语音情感辨认、声学事情检测、逆文本正则化等才能,选用工业级数十万小时的标示音频进行模型练习,确保了模型的通用辨认作用。模型能够被使用于中文、粤语、英语、日语、韩语音频辨认,并输出带有情感和事情的富文本转写成果。
多言语辨认: 选用超越 40 万小时数据练习,支撑超越 50 种言语,辨认作用上优于 Whisper 模型。
富文本辨认:具有优异的情感辨认,能够在测验数据上到达和超越现在最佳情感辨认模型的作用。
支撑声响事情检测才能,支撑音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事情进行检测。
高效推理: SenseVoice-Small 模型选用非自回归端到端结构,推理推迟极低,10s 音频推理仅耗时 70ms,15 倍优于 Whisper-Large。
微调定制: 具有快捷的微调脚本与战略,便利用户依据事务场景修正长尾样本问题。
服务布置: 具有完好的服务布置链路,支撑多并发恳求,支撑客户端言语有,python、c++、html、java 与 c# 等。
CosyVoice 模型相同支撑多言语、音色和情感操控,该模型在多言语语音、零样本语音生成、跨言语语音克隆和指令跟从等功能方面表现出色。
这两款模型都是 FunAudioLLM 系列的,这是一个旨在增强者与大型言语模型之间天然语音交互的结构,然后完成语音翻译、情感语音谈天、交互式博客和赋有表现力的有声读物叙说等使用场景,打破语音交互技能的边界。
现在这些模型已经在 Modelscope 和 HuggingFace 渠道供给,有爱好的开发者能够经过这两个渠道下载模型进行测验,下面是项目地址。
SenseVoice 模型:https://github.com/FunAudioLLM/SenseVoice
CosyVoice 模型:https://github.com/FunAudioLLM/CosyVoice
有关 FunAudioLLM 完好阐明:https://fun-audio-llm.github.io/




还没有评论,来说两句吧...